ERL-2021-Workshop-TDM-Python
Materials to accompany the ER&L 2021 workshop ‘Learn to Text Data Mine Using Jupyter Notebooks on Google Colab’

March 29 – April 8, 2021
https://www.electroniclibrarian.org/learn-to-text-data-mine-with-jupyter-notebooks-on-google-colab/
About
This asynchronous and self-paced workshop is organized into 4 sections and 7 videos. Use this site for links to all resources referenced in each section and video. In the first section, we will briefly introduce a workflow template for text data mining. In the second section, we will introduce Google Colab, Jupyter Notebooks, and write our Hello, World script. In the third section, we will learn the fundamentals of Python scripting. This will encompass two videos. In the fourth section, we will begin to leverage what we learned to focus on libraries that provide text data mining utilities. This section also contains two videos. The final video is a quick summation, mapping what we learned back to the text data mining workflow introduced in the first video.
There is approximately 2 hours of video content. These videos walk you through examples. You can watch and pause the video to follow along. This will provide the deepest learning and will take the most time. Alternatively, you can watch the videos while taking notes and practice later. There are absolutely no rules.
Text Data Mining: Workflow and Topics Covered
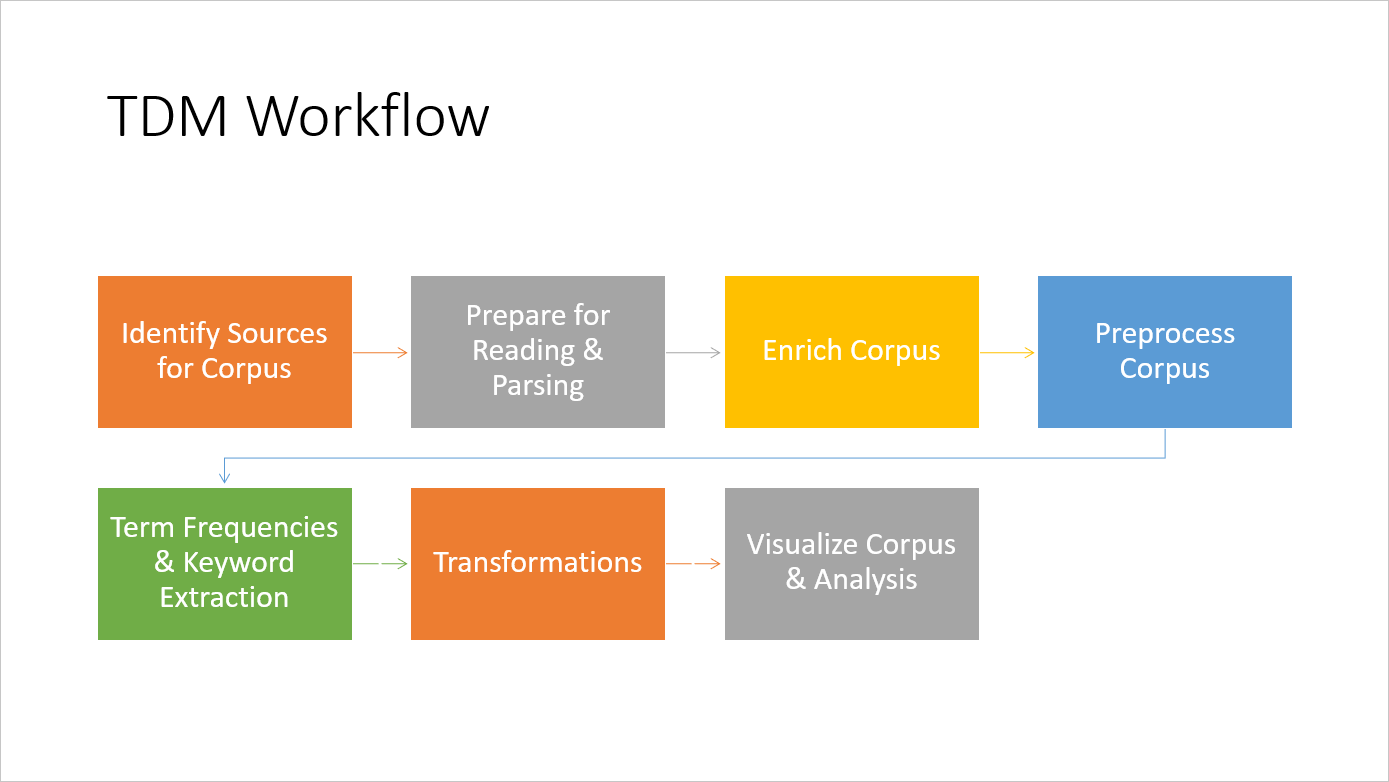
TDM Flexible Workflow Introduced in Video #1
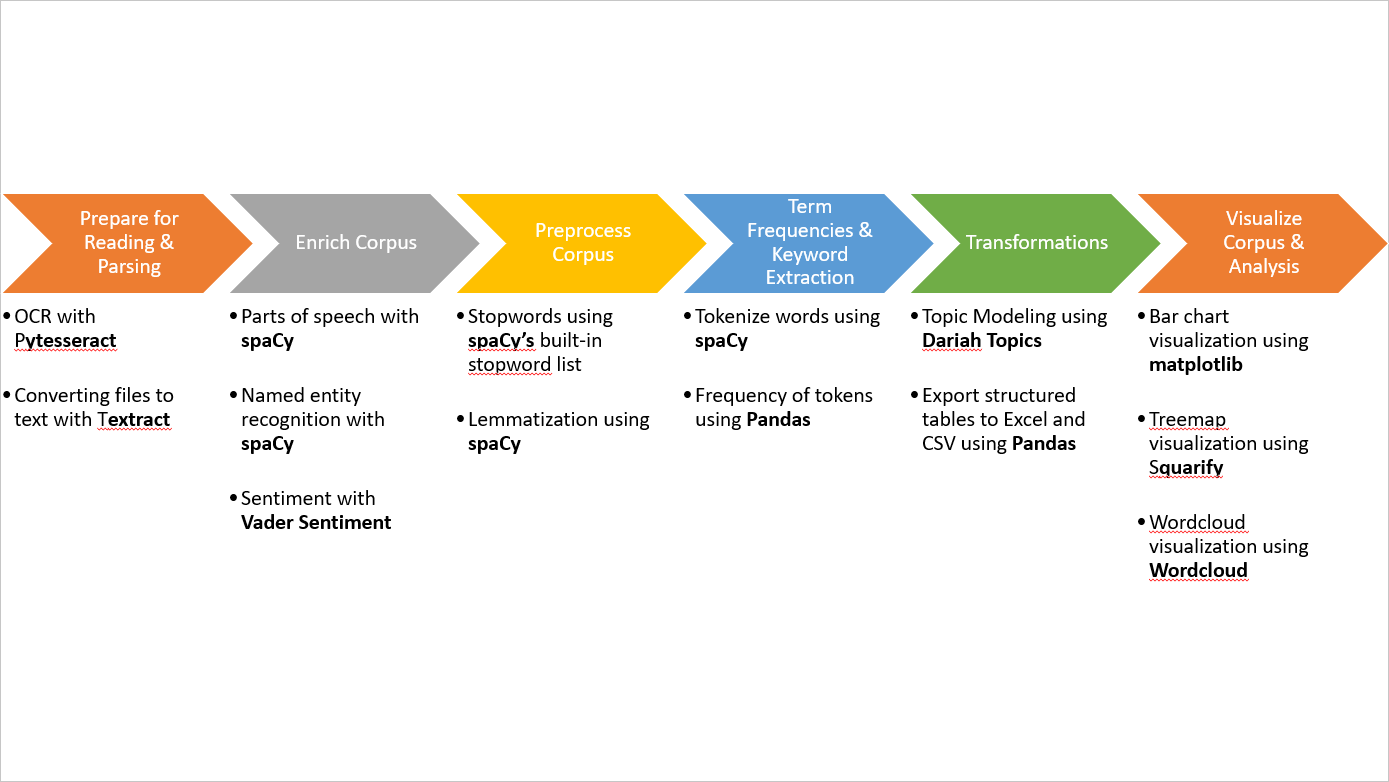
Workshop Introduces the Following Techniques Mapped to Workflow
Office Hours for this Workshop (via Zoom):
- Monday, March 29 @ 1:00pm - 1:30pm Central (Roadmapping/ Kick off session)
- Thursday, April 1 @ 1:00pm - 2:00pm Central
- Thursday, April 8 @ 1:00pm - 2:00pm Central
Section 1: Introduction to Text Data Mining
Video 1 (14:23)
- Covered: Contains an initial slideshow introducing text data mining and then a hands-on walkthrough of an existing Jupyter Notebook to analyze interview transcripts
- Resources Used/Mentioned:
- Practice Files:
- Video
Section 2: Hands-On Introduction to Jupyter Notebooks on Google Colab
Video 2 (10:46)
- Covered: We will explore the Colab environment and the classic ‘Hello, World’ script.
- Resources Used/Mentioned:
- Video
Section 3: Introduction to Python
Video 3 (25:42)
- Covered: Introduction to the following 7 Python Commands: Print, Variable Types, Operators, Input, Indentation Syntax, If Conditions, Reading Text Files.
- Resources Used/Mentioned:
- Practice Files:
- Video
Video 4 (21:16)
- Covered: Introduction to the following 4 Python Commands: Loops, Lists, Concatenations, Functions
- Resources Used/Mentioned:
- Practice Files:
- Video
Section 4: Text Data Mining Using Python
Video 5 (24:53)
- Covered: We will explore and implement simple libraries that provide text data mining utilities.
- Resources Used/Mentioned:
- Practice Files:
- Video
Video 6 (23:17)
- Covered: We will structure text content into a dataframe containing columns for each term, parts of speech, lemmas, named entities, and a stop word indicator.
- Resources Used/Mentioned:
- Practice Files:
- Video
Section 5: Summing Up
Video 7 (2:35)
- Covered: Sum up the workshop, mapping what we learned to the TDM workflow.
- Video
Implementing in libraries
- A workshop participant asked about how implementing and deploying TDM services in libraries. As this may be of interest to others, I am typing a modified version of our email correspondence here.
First, here is an overview of Baylor Library’s Data & Digital Scholarship (DDS) workshop program which includes TDM. Before COVID, we offered three methods of viewing workshop content. In-person, on-demand video modules, and a summer fellowship that combines on-demand video and weekly consultations. Since March 2020, we have temporarily ceased our in-person workshops and so are heavily relying on asynchronous workshop delivery. The structure of the on-demand video modules is very similar to this ER&L workshop, except this would realistically be 4 workshops. Another difference, of course, is building in exercises and flexibility to go in various directions depending on the interests of the participants. Our workshops, whether taken in person or on-demand video, are attached to quizzes in Canvas so that we can offer badging and certificate incentives.
The badging/certificate program is a library program called Data Scholar Program (https://blogs.baylor.edu/digitalscholarship/data-scholar-workshop-program/). It is a library-run program, but we have an advisory group named DRAT (Data Research Advisory Team), an interdisciplinary team of faculty, librarians, and instructional designers who meet monthly and provide direction and support to both the Data Scholar Program and our summer fellowship (https://blogs.baylor.edu/digitalscholarship/fdr-fellowship/). We use Badgr and its Canvas integration to automatically award badges based on completed quizzes. We have had a lot of interest and in the last two years with faculty requiring passing modules as part of their classes. If you head to the Data Scholar Program’s website, at the bottom you can use the embedded Power BI widget to view the modules we currently offer.
Second, the digital humanities/text data mining consultations. As we provide support for data research in general, including data viz, GIS, and TDM, most inquiries for support are at a project level. Meaning, rarely do faculty or students request support for granular text data mining functions. Common TDM-focused questions that we receive at least once per month include, “I want to measure the impact or influence of one author’s works with another author’s works”, or “I am looking to analyze the hashtags or language used in these social media posts”, or “I have these documents and I want to identify every piece of text where someone discusses a concept (such as remorse)”, or in the past year we have been receiving an increasing number of requests to generate maps of locations identified in works. There are three levels of TDM tools we support. First are QDA tools, such as NVivo and Atlas.ti. These are the easiest to use and learn and we have various on-demand modules on QDA. Second are TDM tools that require no programming support. Voyant Tools, while more exploratory than analytical, fits here. My favorite TDM suite of tools are Laurence Anthony’s Ant Tools. AntConc is the most popular tool, but his website provides dozens of free cross-platform TDM utilities. A gold mine! We have video modules on both Voyant Tools and AntConc. In those cases where the first two levels of TDM tools are insufficient for the task, we turn to Python. First, if Python is required and the researcher has limited experience, I require them to pass the video modules on Python I and II first. If the research needs a common request, I often point them to an already-created Notebook on Colab and walk them through how to implement the script. Examples include NCapture Twitter Frequencies and Similarity and Top Keywords. If small adjustments are required to a common script, I will usually make those adjustments and share the Notebook with them. For more complex projects, there are two directions I usually take. (1) I recommend them to apply for the summer fellowship, which in addition to required video module content, includes a 1-hour consultation every week throughout the summer. (2) If the project is from faculty and the project has a good fit with the library’s mission, I try to negotiate a partnership where the Library partners with the researcher(s) and will be responsible for the development of a Notebook for co-authorship and/or co-PI on any research grants if applicable. I am always involved in 1 or 2 of these partnerships at any given time.
Another consideration not yet discussed here is the content source. This will also drive what tools and/or advice is given. If the content is in Gale, we have the Gale Digital Scholar Lab, which provides access to some point and click TDM exploratory functions. Their content can also be downloaded, which means they be analyzed using any of the tools mentioned above. JSTOR/Portico now has Constellate, which has some point and click TDM functionality, but also provides hosted Jupyter Notebook support. The Hathi Trust Research Center provides a handful of point and click tools, but their data capsules allow access to their content via controlled remote desktop environment, where various tools, such as Voyant Tools, AntConc, and also where Python can be run.